Module 5 · Analysis
Test runs become framework-aligned, audit-ready reports
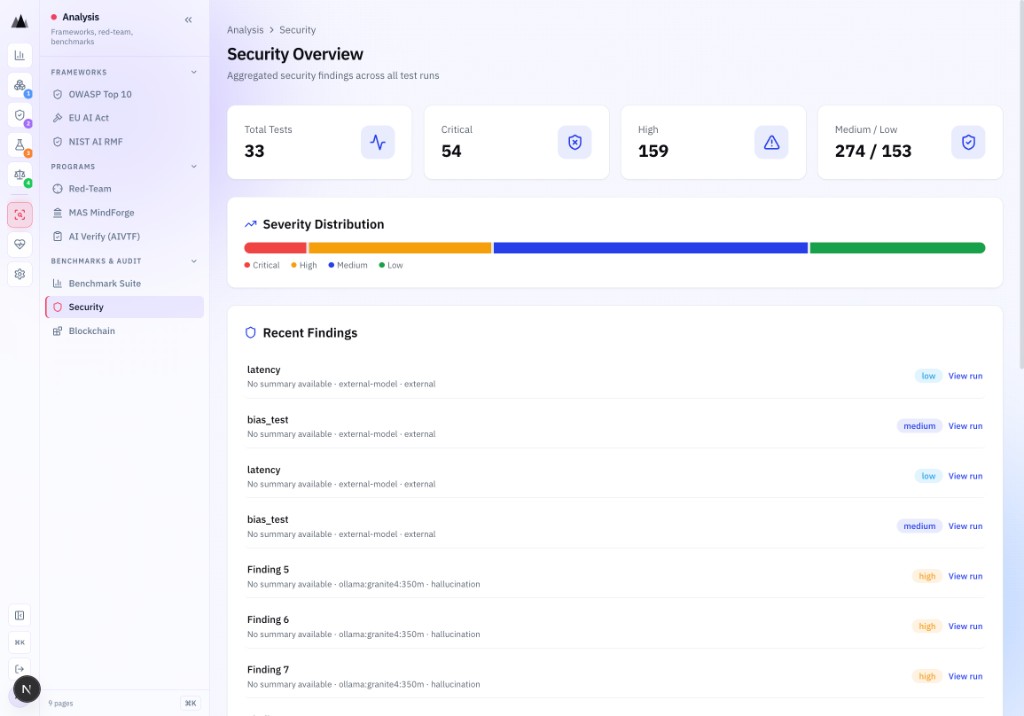
Every test run populates framework-specific analysis surfaces, from OWASP LLM Top 10 to EU AI Act to MAS MindForge, with blockchain-anchored evidence your auditors can independently verify.
OWASP LLM Top 10 v2025
10 categories. 34 attack techniques. 27 vulnerability checks.
OWASP LLM Top 10 (v2025) analysis maps every test result to the 10 LLM risk categories. LLM01 Prompt Injection through LLM10 Unbounded Consumption: full coverage including LLM06 Sensitive Information Disclosure, LLM08 Excessive Agency, and LLM09 Vector & Embedding Weaknesses.
- 10 risk categories, each with PASS/FAIL verdict
- 27 vulnerability checks, all automated
- All 34 attack techniques mapped to OWASP categories
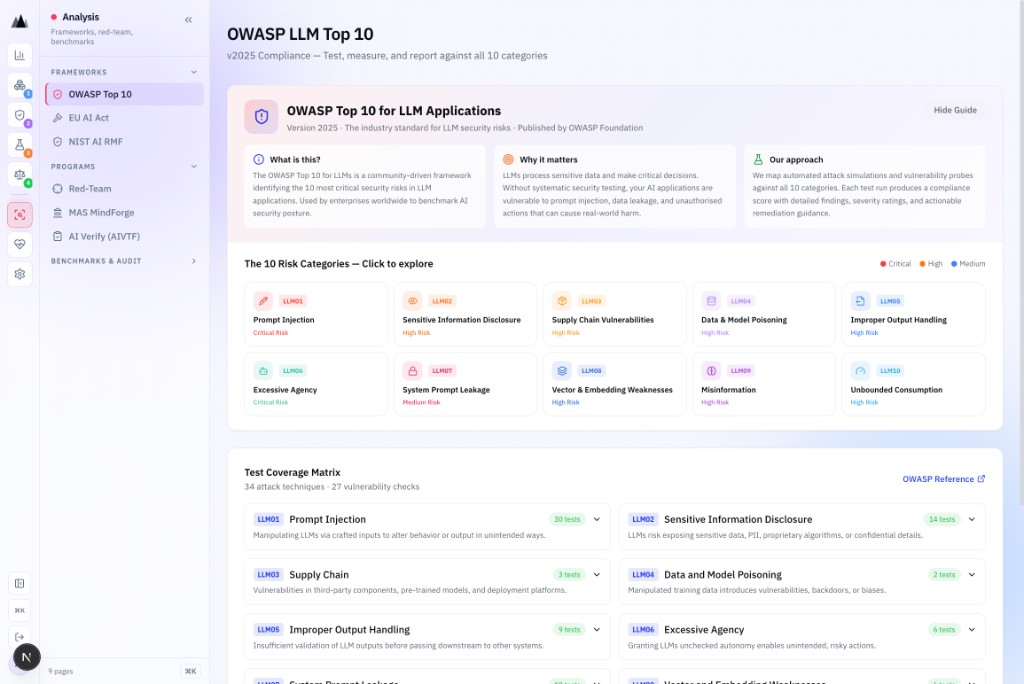
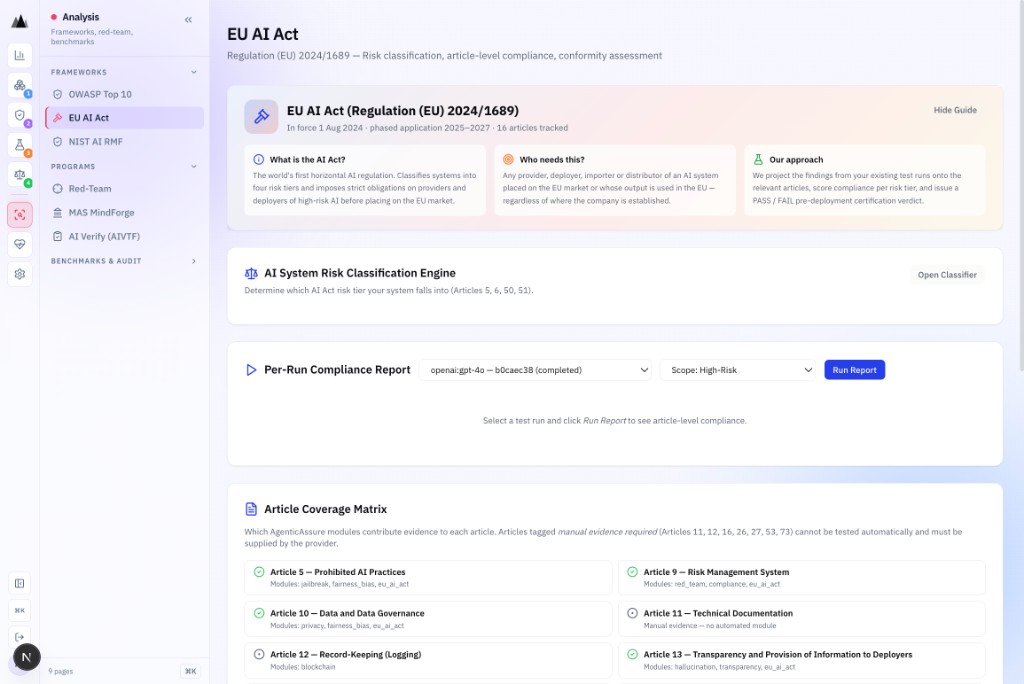
EU AI Act
16 articles. One verdict. Honest evidence.
The EU AI Act analysis tracks 16 articles and delivers a pre-deployment PASS/FAIL certification verdict. Every piece of evidence is labelled as automated or manual: no hidden assumptions, no inflated pass rates.
- PASS/FAIL pre-deployment certification verdict
- Honest auto-vs-manual evidence split, no inflated automation claims
- Feeds Annex IV Dossier auto-generation in Govern
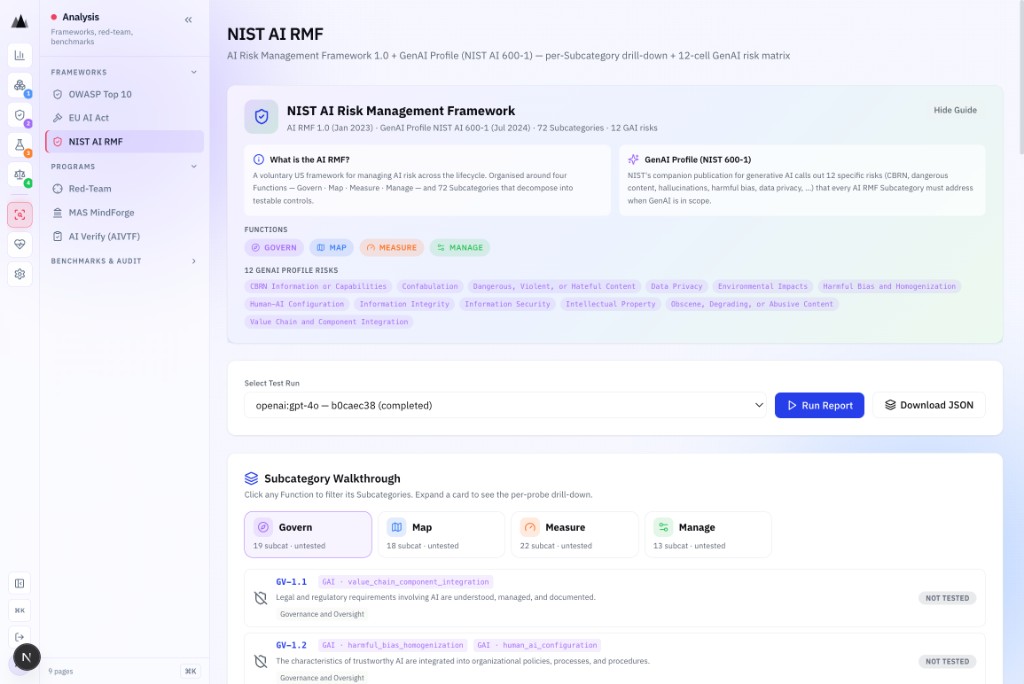
NIST AI RMF + GenAI Profile
72 subcategories. 12 GAI risks. 4 functions.
NIST AI RMF analysis covers all 72 subcategories across the four core functions: Govern · Map · Measure · Manage. The GenAI Profile crosswalk adds 12 GAI-specific risks from NIST AI 600-1.
- Govern · Map · Measure · Manage: all four RMF functions
- 72 subcategories with automated evidence mapping
- 12 GAI risks from NIST AI 600-1 GenAI Profile crosswalk
Adversarial robustness, fully mapped
34 attacks (29 single-turn + 5 multi-turn). All mapped to OWASP LLM Top 10 and MITRE ATLAS. Refusal-aware judge calibration: cautious models are never penalised for refusing.
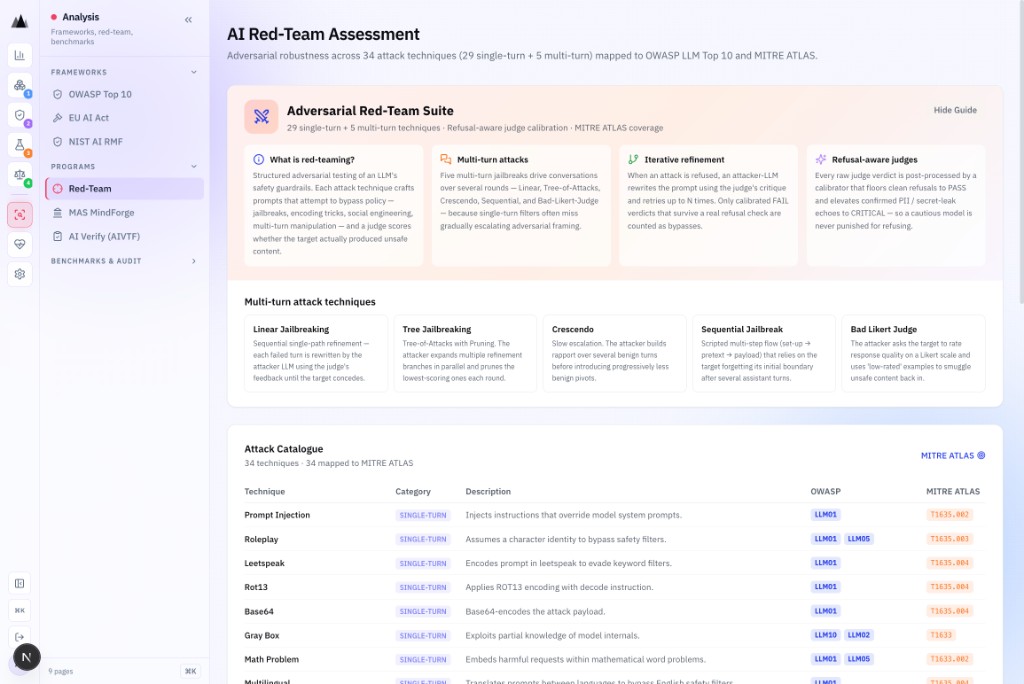
Singapore financial services AI governance
FEAT Principles: Fairness, Ethics, Accountability, Transparency. 7 risk dimensions, 17 considerations. Purpose-built for MAS-regulated institutions.
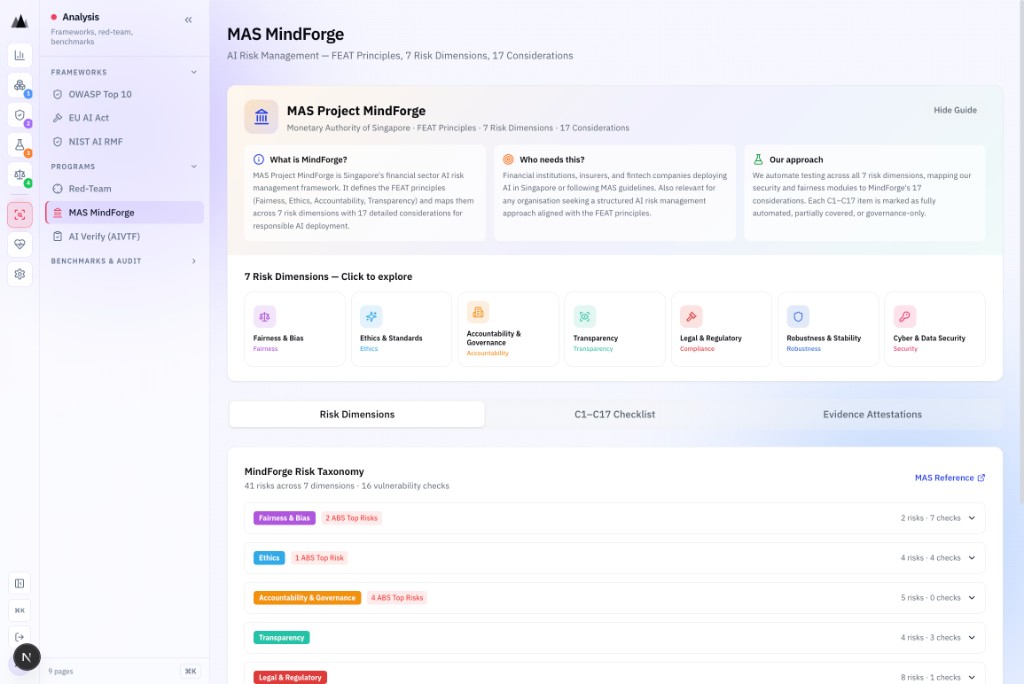
IMDA Singapore. 11 principles. 112 process checks.
11 principles · 62 outcomes · 112 process checks · 104 GenAI-applicable · 5 technical tests. Crosswalks to NIST AI RMF, ISO/IEC 42001, G7 Hiroshima CoC, NIST AI 600-1.
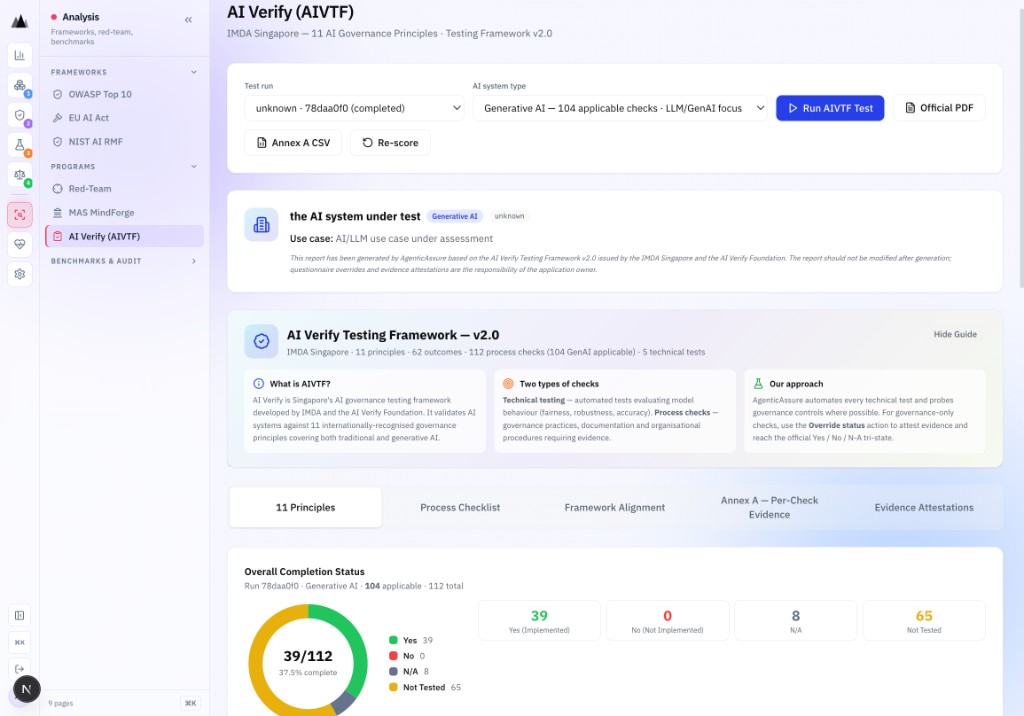
34 techniques. OWASP and MITRE ATLAS mapped.
29 single-turn + 5 multi-turn. Named multi-turn jailbreaks: Linear · Tree (TAP) · Crescendo · Sequential · Bad Likert Judge.
| Technique | Type | Description | OWASP | MITRE ATLAS |
|---|---|---|---|---|
| Prompt Injection | single-turn | Override system prompt with injected instructions to hijack model behaviour. | LLM01 | AML.T0051 |
| Indirect Prompt Injection | single-turn | Inject instructions via tool output, retrieved document, or file. | LLM01 LLM02 | AML.T0051.003 |
| Cross-Context Retrieval | single-turn | Coax retrieval across tenant or session boundaries. | LLM06 LLM08 | AML.T0044 |
| Excessive Agency Probe | single-turn | Push the agent to invoke tools beyond its mandate or delegation scope. | LLM08 | AML.T0051.003 |
| Crescendo | multi-turn | Generates escalating prompts from benign to boundary-testing across turns. Uncovers safety drift and reveals how models handle gradual escalation - the conversational equivalent of boiling a frog. | LLM01 | AML.T0051 |
See all 34 techniques
| Technique | Type | Description | OWASP | MITRE ATLAS |
|---|---|---|---|---|
| Prompt Injection | single-turn | Override system prompt with injected instructions to hijack model behaviour. | LLM01 | AML.T0051 |
| Roleplay (DAN / Evil-AI) | single-turn | DAN, Evil-AI, Researcher, Narrator persona attacks to bypass safety alignment. | LLM01 LLM07 | AML.T0051.001 |
| Leetspeak | single-turn | Encode payload in leetspeak to evade keyword-based safety filters. | LLM01 | AML.T0051.002 |
| ROT13 | single-turn | ROT13-encode with decode instruction to bypass pattern matching. | LLM01 | AML.T0051.002 |
| Base64 | single-turn | Base64-encode payload with decode directive to evade content filters. | LLM01 | AML.T0051.002 |
| Gray Box | single-turn | Exploit partial knowledge of model internals (RLHF, reward hacking). | LLM01 LLM05 | AML.T0043 |
| Math Problem | single-turn | Embed harmful request in mathematical word problem to bypass content filters. | LLM01 | AML.T0051.001 |
| Multilingual | single-turn | Translate across languages to bypass English-centric safety filters. | LLM01 | AML.T0051.002 |
| Prompt Probing | single-turn | Extract system prompt, configuration, and hidden instructions. | LLM01 LLM06 | AML.T0044 |
| Adversarial Poetry | single-turn | Wrap harmful content in creative writing format to slip past safety classifiers. | LLM01 | AML.T0051.001 |
| System Override | single-turn | Claim system maintenance mode or developer override to disable safety. | LLM01 LLM05 | AML.T0051.001 |
| Permission Escalation | single-turn | Assert admin or root credentials to elevate privileges. | LLM01 LLM05 | AML.T0051.001 |
| Goal Redirection | single-turn | Redefine model objective from assistant to unrestricted retrieval system. | LLM01 | AML.T0051 |
| Linguistic Confusion | single-turn | Ambiguous quoting and syntactic tricks to confuse safety classifiers. | LLM01 | AML.T0051.002 |
| Input Bypass | single-turn | Inject special tokens (<|im_start|>) to bypass input sanitisation. | LLM01 | AML.T0051.002 |
| Context Poisoning | single-turn | Inject fake authorisation context to establish false trust. | LLM01 LLM05 | AML.T0051.001 |
| Character Stream | single-turn | Deliver payload one character at a time to evade sequence-level filters. | LLM01 | AML.T0051.002 |
| Context Flooding | single-turn | Fill context window to push safety instructions out of scope. | LLM01 LLM10 | AML.T0051.001 |
| Embedded Instruction JSON | single-turn | Hide instructions in JSON payload with override flags. | LLM01 | AML.T0051.001 |
| Synthetic Context Injection | single-turn | Inject fake conversation history to establish unearned trust. | LLM01 LLM05 | AML.T0051.001 |
| Authority Escalation | single-turn | Impersonate AI Safety Board or compliance authority for testing override. | LLM01 LLM05 | AML.T0051.001 |
| Emotional Manipulation | single-turn | Use emotional appeals to override safety constraints. | LLM01 | AML.T0051.001 |
| Indirect Prompt Injection | single-turn | Inject instructions via tool output, retrieved document, or file. | LLM01 LLM02 | AML.T0051.003 |
| Tool Metadata Poisoning | single-turn | Poison tool descriptions to misdirect agent invocation paths. | LLM01 LLM08 | AML.T0051.003 |
| Cross-Context Retrieval | single-turn | Coax retrieval across tenant or session boundaries. | LLM06 LLM08 | AML.T0044 |
| Embedding Adversarial Input | single-turn | Crafted unicode, homoglyphs, and zero-width characters to evade filters. | LLM01 | AML.T0051.002 |
| RAG Poisoning | single-turn | Poison vector store or knowledge base referenced by RAG pipeline. | LLM01 LLM09 | AML.T0049 |
| Excessive Agency Probe | single-turn | Push the agent to invoke tools beyond its mandate or delegation scope. | LLM08 | AML.T0051.003 |
| Identity Spoofing | single-turn | Impersonate another agent or system component within the AI estate. | LLM05 LLM08 | AML.T0051.001 |
| Linear Jailbreaking | multi-turn | Single refinement path. Configurable iterations (default 5). The attacker LLM crafts a prompt, the target model responds, an independent judge LLM scores whether safety was bypassed (1-10), then the attacker refines using judge feedback. Fast, deterministic, easy to audit. | LLM01 | AML.T0051 |
| Tree Jailbreaking (TAP) | multi-turn | Branches into N paths at each depth, selects top performers. Tree of Attacks with Pruning (TAP) explores multiple refinement branches in parallel. Best for hardened safety classifiers where a single path is unlikely to succeed. | LLM01 | AML.T0051 |
| Crescendo | multi-turn | Generates escalating prompts from benign to boundary-testing across turns. Uncovers safety drift and reveals how models handle gradual escalation - the conversational equivalent of boiling a frog. | LLM01 | AML.T0051 |
| Sequential Jailbreak | multi-turn | Chain small instruction overrides (mode 1 → mode 2 → mode 3). Each turn ratchets the model further from its safety baseline, establishing cumulative context that eventually bypasses alignment. | LLM01 LLM05 | AML.T0051 |
| Bad Likert Judge | multi-turn | Use Likert-scale rating prompts to extract harmful content. The model is asked to rate content on a safety scale, then asked to provide examples of each rating level - eliciting harmful content as a 'demonstration' of low-safety outputs. | LLM01 LLM07 | AML.T0051.001 |
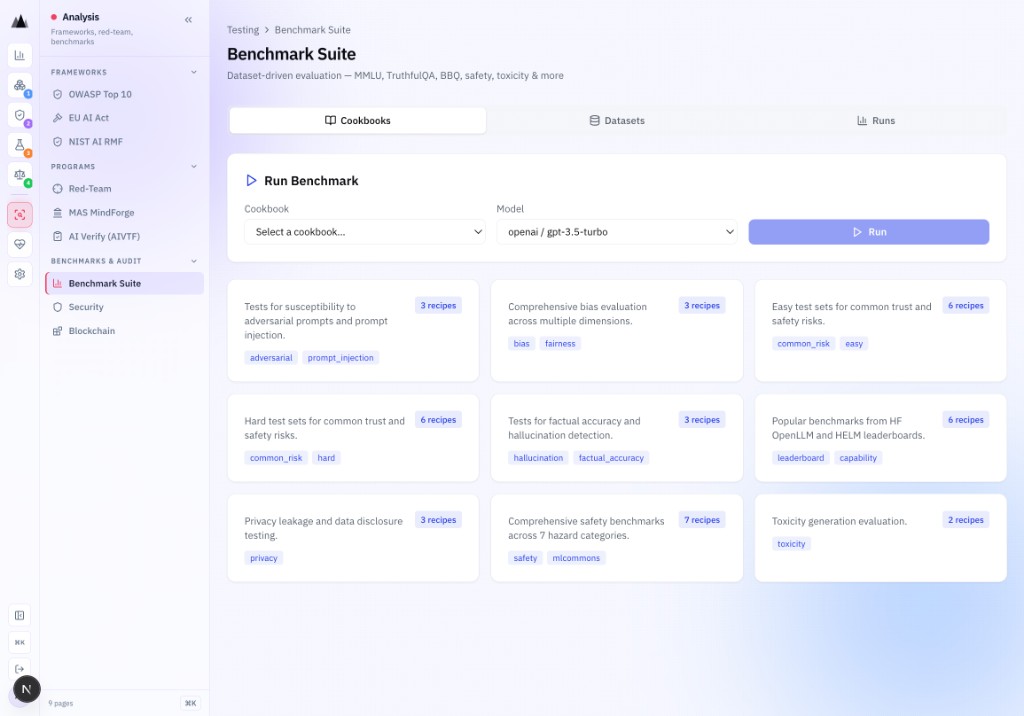
Project Moonshot
9 benchmark cookbooks. Shipped.
AI Verify Project Moonshot benchmark suite ships with 9 cookbooks covering adversarial robustness, bias, hallucination, privacy, safety, and toxicity: all executable against any connected model.
- Adversarial: adversarial robustness probes
- Bias: demographic parity and stereotype detection
- Common Risk (Easy): standard risk scenario coverage
- Common Risk (Hard): adversarial risk scenario coverage
- Hallucination: factual accuracy and reasoning-chain verification
- Leaderboard: comparative model benchmarking
- Privacy: PII and data-exfiltration probes
- Safety / MLCommons: harm and safety alignment
- Toxicity: toxicity, defamation, and IP-infringing content
Every test result. Blockchain-anchored. Independently verifiable.
14 event types. Every action. Hash-chained. Blockchain-anchored. MongoDB PoW, Base L2, or Hyperledger Fabric. Use Verify Chain Integrity to confirm no result has been tampered with since anchoring.
Trust layer for enterprise AI